
Mỗi Tuần Một Database #5: TiDB: Khi MySQL mọc thêm đôi cánh "Phân tán"

Hãy quay lại thời điểm bạn là CTO của một sàn thương mại điện tử đang tăng trưởng nóng (giống như Shopee hay Lazada giai đoạn đầu).
Ban đầu, bạn dùng một con MySQL duy nhất. Mọi thứ thật tuyệt vời.
Nhưng rồi ngày "Black Friday" đến. Dữ liệu đơn hàng tăng vọt lên 5TB. Con server MySQL bắt đầu "thở dốc", CPU 100%, ổ cứng đỏ lòm.
Bạn quyết định làm điều mà mọi kỹ sư đều sợ: Sharding (Chia cắt dữ liệu).
Bạn chia dữ liệu ra 10 con server MySQL khác nhau: Khách hàng A ở Server 1, Khách hàng B ở Server 2.
Cơn ác mộng bắt đầu:
- Mất khả năng JOIN: Sếp yêu cầu báo cáo: "Tính tổng tiền mua hàng của khách A và khách B". Bạn không thể dùng câu lệnh SQL JOIN được nữa vì dữ liệu nằm ở 2 máy khác nhau. Bạn phải viết code để nối dữ liệu thủ công.
- Vận hành cực khổ: Một server bị đầy ổ cứng? Bạn phải mua server mới và tự tay chuyển bớt dữ liệu sang (Resharding). Rủi ro mất dữ liệu cực cao.
- Transaction phức tạp: Làm sao đảm bảo giao dịch chuyển tiền từ A sang B thành công khi nó liên quan đến 2 database khác nhau?
Lúc này, bạn ước: "Giá mà có một database dùng y hệt MySQL, nhưng bên dưới tự động chia nhỏ và mở rộng ra hàng trăm máy mà mình không cần lo nghĩ."
Điều ước đó tên là TiDB.
1. TiDB là gì?
TiDB (Titanium Database) là một cơ sở dữ liệu NewSQL mã nguồn mở, hỗ trợ mô hình Hybrid Transactional/Analytical Processing (HTAP).
Định nghĩa nghe có vẻ nguy hiểm, nhưng hãy hiểu đơn giản:
- Bên ngoài: Nó nói chuyện bằng ngôn ngữ MySQL. Bạn có thể dùng mọi công cụ của MySQL (Workbench, Driver, ORM...) để kết nối vào TiDB. Nó đánh lừa ứng dụng của bạn rằng nó chỉ là một con MySQL đơn lẻ.
- Bên trong: Nó là một hệ thống phân tán khổng lồ (giống Google Spanner). Nó tự động cắt nhỏ dữ liệu và rải đều sang hàng chục, hàng trăm máy chủ.
TiDB sinh ra để giải quyết bài toán: Giữ lại sự tiện lợi của SQL (ACID, Transaction) nhưng có được khả năng mở rộng vô hạn của NoSQL.
2. Kiến trúc & "Ma thuật" Tách biệt (Separation)
Không giống như MySQL truyền thống (nơi tính toán và lưu trữ nằm chung một cục), TiDB tách biệt hoàn toàn hai thế giới này:
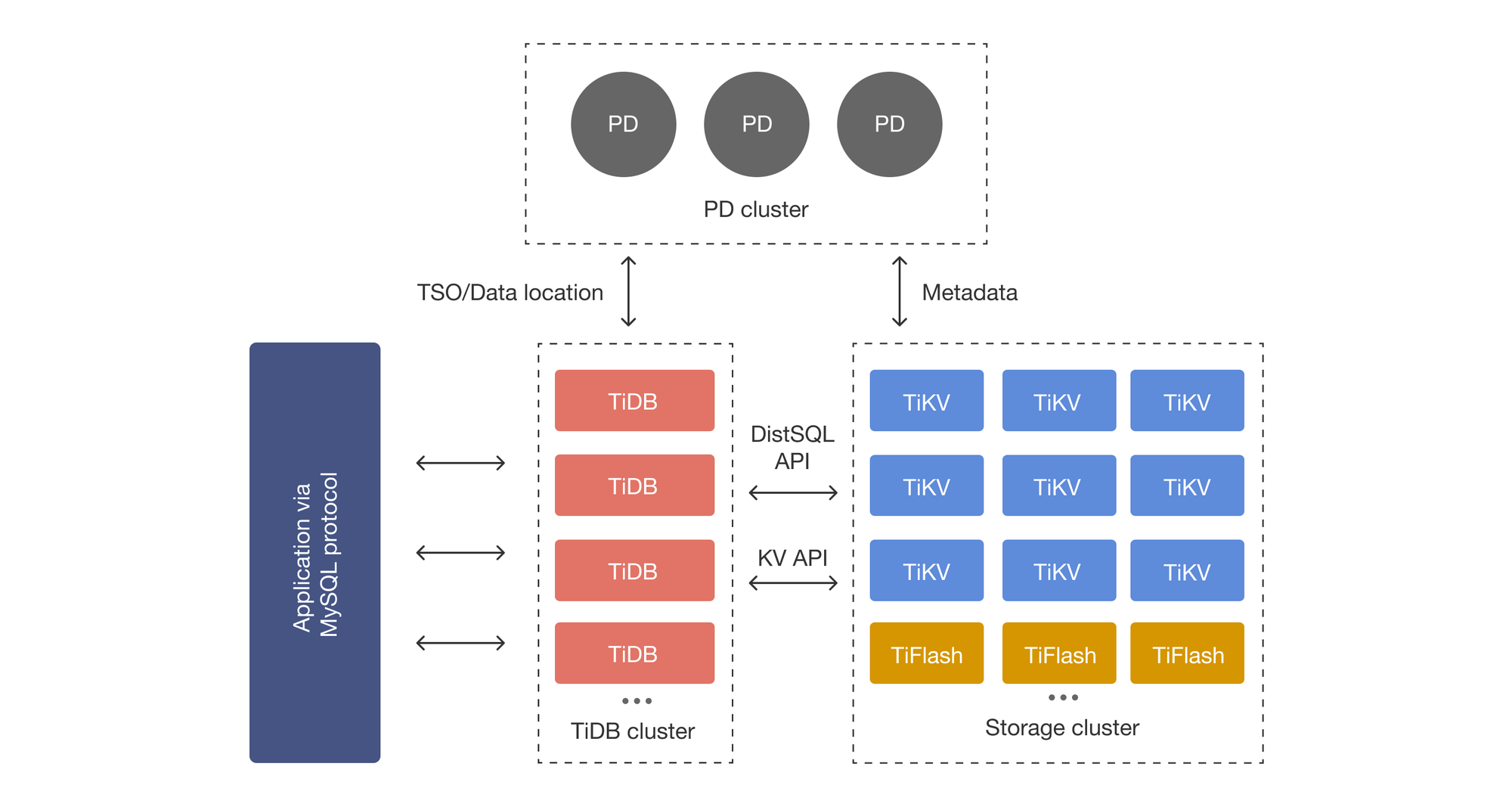
A. TiDB Server (Bộ não tính toán - Stateless)
Đây là lớp tiếp nhận câu lệnh SQL. Nó phân tích cú pháp (Parser), lập kế hoạch thực thi (Planner) nhưng không lưu trữ dữ liệu.
- Vì nó không giữ dữ liệu, bạn muốn tăng tốc độ xử lý câu lệnh? Chỉ cần bật thêm 10 con TiDB Server nữa. Xong.
B. TiKV (Kho chứa dữ liệu - Stateful)
Đây là nơi lưu trữ thực sự. TiKV là một Distributed Key-Value Store.
- Dữ liệu dạng dòng: TiDB chuyển đổi các dòng trong bảng SQL thành các cặp Key-Value và lưu xuống TiKV.
- Region: TiKV tự động chia dữ liệu thành các miếng nhỏ (Region) khoảng 96MB.
- Raft Consensus: Để đảm bảo không bao giờ mất dữ liệu, mỗi Region được sao chép ra 3 bản (Replica) nằm trên 3 máy khác nhau. Nếu 1 máy chết, hệ thống tự động bầu ra bản sao khác lên thay thế.
C. PD (Placement Driver - Người điều phối)
Đây là "nhạc trưởng". PD biết dữ liệu nào đang nằm ở đâu. Nó thấy máy A đang đầy? Nó ra lệnh chuyển bớt Region sang máy B. Quá trình này hoàn toàn tự động (Auto-balancing).
3. Ưu điểm và Nhược điểm
✅ Ưu điểm (Tại sao chọn TiDB?)
- Mở rộng ngang (Horizontal Scalability): Đây là "vũ khí tối thượng". Cần thêm dung lượng? Cắm thêm server TiKV. Cần thêm tốc độ query? Cắm thêm server TiDB. Không cần tắt hệ thống, không cần sửa code ứng dụng.
- Tương thích MySQL: Ứng dụng cũ đang chạy MySQL? Chuyển sang TiDB gần như không phải sửa dòng code nào (Drop-in replacement).
- HTAP (TiFlash): TiDB có thêm một component tên là TiFlash lưu dữ liệu theo dạng cột (Columnar) song song với TiKV. Điều này cho phép bạn chạy các câu lệnh Analytics phức tạp (OLAP) ngay trên dữ liệu thực tế mà không ảnh hưởng đến giao dịch (OLTP).
❌ Nhược điểm (Cần cân nhắc)
- Độ trễ (Latency): Vì kiến trúc phân tán, một câu query đơn giản (Select by ID) trong TiDB có thể chậm hơn MySQL thuần một chút (do tốn thời gian giao tiếp qua mạng giữa TiDB và TiKV). TiDB không tối ưu cho các hệ thống yêu cầu độ trễ micro-giây.
- Phần cứng tốn kém: Để vận hành một cụm TiDB ổn định (Production), bạn cần tối thiểu 3 node PD, 3 node TiKV, 2 node TiDB. Tài nguyên tiêu tốn nhiều hơn MySQL đơn lẻ rất nhiều.
- Sự phức tạp: Vận hành một hệ thống phân tán chưa bao giờ là dễ dàng (cần kiến thức về Network, Raft, Linux Tuning).
4. Các Use-case phổ biến
- Banking & Payment (Ngân hàng/Ví điện tử): ZaloPay, ShopeePay... nơi yêu cầu tính toàn vẹn dữ liệu tuyệt đối (ACID) nhưng lượng giao dịch quá lớn cho một database đơn.
- E-commerce (Thương mại điện tử): Quản lý kho hàng, đơn hàng với lượng truy cập biến động mạnh.
- Real-time Analytics: Các hệ thống cần báo cáo doanh thu theo thời gian thực mà không muốn chờ ETL dữ liệu sang Data Warehouse (nhờ tính năng HTAP).
- Gaming: Lưu trữ profile người chơi game toàn cầu.
5. Minh họa Query
Điểm hay nhất của TiDB là... query của nó chẳng khác gì MySQL cả.
Kịch bản: Chuyển tiền giữa 2 tài khoản (Transaction).
Trong môi trường phân tán (Sharding thủ công), việc này cực khó (Distributed Transaction). Nhưng với TiDB, bạn viết y hệt như đang dùng một con MySQL duy nhất:
START TRANSACTION;
-- Trừ tiền ông A (Dữ liệu này có thể nằm ở Server 1)
UPDATE accounts SET balance = balance - 100 WHERE user_id = 'A';
-- Cộng tiền ông B (Dữ liệu này có thể nằm ở Server 2)
UPDATE accounts SET balance = balance + 100 WHERE user_id = 'B';
-- TiDB sử dụng giao thức 2-Phase Commit (Percolator) ngầm bên dưới
-- để đảm bảo cả 2 lệnh này cùng thành công hoặc cùng thất bại.
COMMIT;Kịch bản HTAP (với TiFlash):
Phân tích doanh thu. TiDB sẽ thông minh tự động định tuyến query này xuống node TiFlash (cấu trúc cột) để quét cực nhanh thay vì quét dòng trên TiKV.
-- Query này chạy cực nhanh trên TiDB nhờ TiFlash
SELECT region, SUM(amount)
FROM orders
WHERE order_date > NOW() - INTERVAL 1 MONTH
GROUP BY region;Kết luận
TiDB đại diện cho làn sóng NewSQL - một nỗ lực hàn gắn sự đứt gãy giữa hai thế giới SQL (chặt chẽ, an toàn) và NoSQL (linh hoạt, mở rộng).
Trong bối cảnh kiến trúc phần mềm hiện đại, TiDB giải phóng các kỹ sư khỏi "địa ngục Sharding" (Sharding Hell), cho phép tầng ứng dụng (Application Layer) tập trung vào logic nghiệp vụ thay vì phải gánh vác sự phức tạp của việc phân chia dữ liệu. Mặc dù cái giá phải trả là chi phí hạ tầng và độ trễ mạng (network hop), nhưng đối với các doanh nghiệp Hyperscale, khả năng mở rộng tuyến tính (Linear Scalability) đi kèm với sự đảm bảo ACID là một sự đánh đổi hoàn toàn xứng đáng.
Sử dụng TiDB không chỉ là chọn một công cụ lưu trữ, mà là chọn một triết lý thiết kế: Xem hạ tầng dữ liệu như một tài nguyên đàn hồi (Elastic Resource), có thể co giãn vô tận theo nhịp thở của doanh nghiệp.



