
Mỗi Tuần Một Database #4: InfluxDB: "Cỗ máy thời gian" lưu giữ nhịp đập của thế giới số
Hãy thử tưởng tượng bạn là Kỹ sư Vận hành (Operations Engineer) tại CERN (Tổ chức Nghiên cứu Hạt nhân Châu Âu). Bạn đang chịu trách nhiệm giám sát Máy gia tốc hạt lớn (LHC). Hệ thống này không ngủ: hơn 100.000 cảm biến liên tục gửi về các chỉ số nhiệt độ, áp suất, từ trường... với tần suất 100 mili-giây một lần.
Đột nhiên, một cảnh báo đỏ xuất hiện: Nhiệt độ tại nam châm siêu dẫn số 4 tăng bất thường.
Để ngăn chặn một vụ nổ trị giá hàng tỷ đô la, bạn cần ngay lập tức vẽ biểu đồ biến động nhiệt độ của nam châm này trong 10 phút vừa qua để xác định nguyên nhân.

Nếu hệ thống của bạn đang lưu dữ liệu này vào một Relational Database (RDBMS) truyền thống như MySQL hay PostgreSQL, bạn đang gặp rắc rối lớn:
- Vấn đề Ghi (Write): Với 100.000 cảm biến x 10 lần/giây, bạn đang nạp vào 1 triệu bản ghi mỗi giây. MySQL phải liên tục cập nhật và cân bằng lại cấu trúc B-Tree Index cho mỗi lần ghi. Ổ cứng (Disk I/O) bị nghẽn hoàn toàn chỉ để phục vụ việc ghi.
- Vấn đề Đọc (Read): Khi bạn chạy câu lệnh SELECT * FROM sensors WHERE time > NOW() - 10m, database phải quét qua một bảng khổng lồ chứa hàng tỷ dòng (Table Scan) trong khi ổ cứng vẫn đang bận rộn ghi dữ liệu mới.
- Kết quả: Câu truy vấn bị treo (Time out). Hệ thống bị khóa (Lock). Bạn không thấy được dữ liệu. Thảm họa xảy ra.
CERN cần một giải pháp không bị "tắc nghẽn" bởi chính cấu trúc chỉ mục của nó. Họ cần một cơ sở dữ liệu có thể nuốt trọn hàng triệu dòng mỗi giây theo dạng tuần tự (sequential write) và truy xuất lại theo trục thời gian trong nháy mắt.
Giải pháp đó chính là Time Series Database (TSDB), và cái tên tiêu biểu nhất là InfluxDB.
Trong kỷ nguyên của IoT và DevOps, InfluxDB không lưu trữ "trạng thái hiện tại" (như số dư tài khoản trong SQL), mà nó lưu trữ "lịch sử biến động". Vậy điều gì khiến nó trở thành chuẩn mực cho dữ liệu chuỗi thời gian?
1. InfluxDB là gì?
InfluxDB là một cơ sở dữ liệu chuỗi thời gian (Time Series Database - TSDB) mã nguồn mở, được viết bằng ngôn ngữ Go.
Khác với RDBMS (tối ưu cho giao dịch chính xác) hay Elasticsearch (tối ưu cho tìm kiếm văn bản), InfluxDB được sinh ra với một mục đích duy nhất: Xử lý khối lượng ghi cực lớn (High Write Throughput) và truy vấn dữ liệu theo trục thời gian với độ trễ thấp.
Nó là mảnh ghép trung tâm của TICK Stack (Telegraf, InfluxDB, Chronograf, Kapacitor) - bộ công cụ giám sát cạnh tranh trực tiếp với Prometheus trong mảng Observability (Khả năng quan sát hệ thống).
2. Kiến trúc & "Ma thuật" TSM Tree
Nếu HBase dùng LSM Tree, Elasticsearch dùng Inverted Index, thì sức mạnh của InfluxDB nằm ở TSM (Time-Structured Merge Tree).
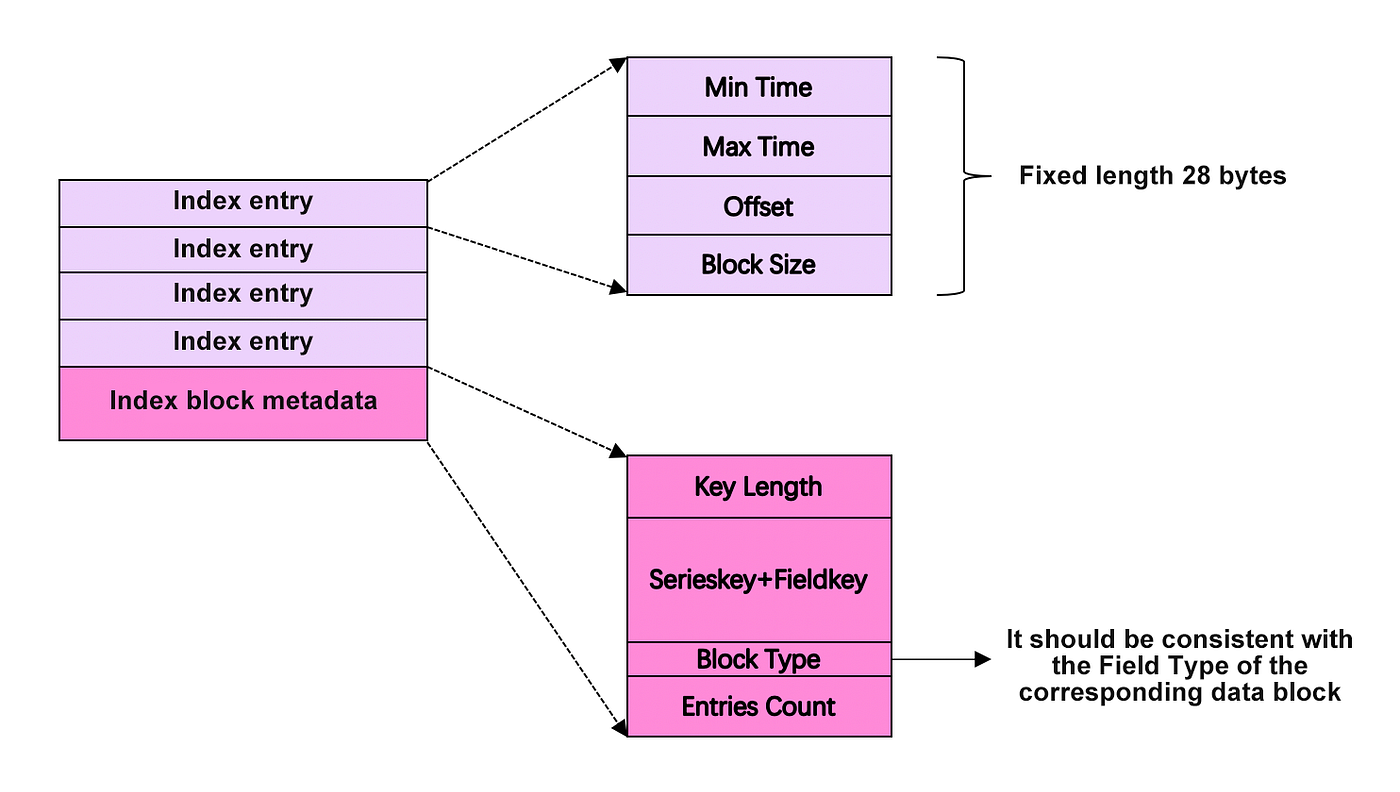
TSM hoạt động ra sao?
Trong các DB thường, dữ liệu được sắp xếp ngẫu nhiên hoặc theo ID. Nhưng trong InfluxDB, Thời gian (Timestamp) là công dân hạng nhất.
Hãy tưởng tượng bạn quay video một bông hoa nở.
- Thay vì lưu lại toàn bộ bức ảnh ở mỗi khung hình (tốn dung lượng), InfluxDB chỉ lưu lại sự thay đổi (delta) giữa các khung hình.
- Nó sử dụng các thuật toán nén chuyên biệt (như Gorilla compression của Facebook) để nén các dãy số float, integer cực kỳ hiệu quả. 1GB dữ liệu thô có thể được nén xuống chỉ còn vài chục MB trên đĩa.
Các thành phần dữ liệu (Line Protocol):
InfluxDB không dùng JSON hay SQL Table, nó dùng Line Protocol:
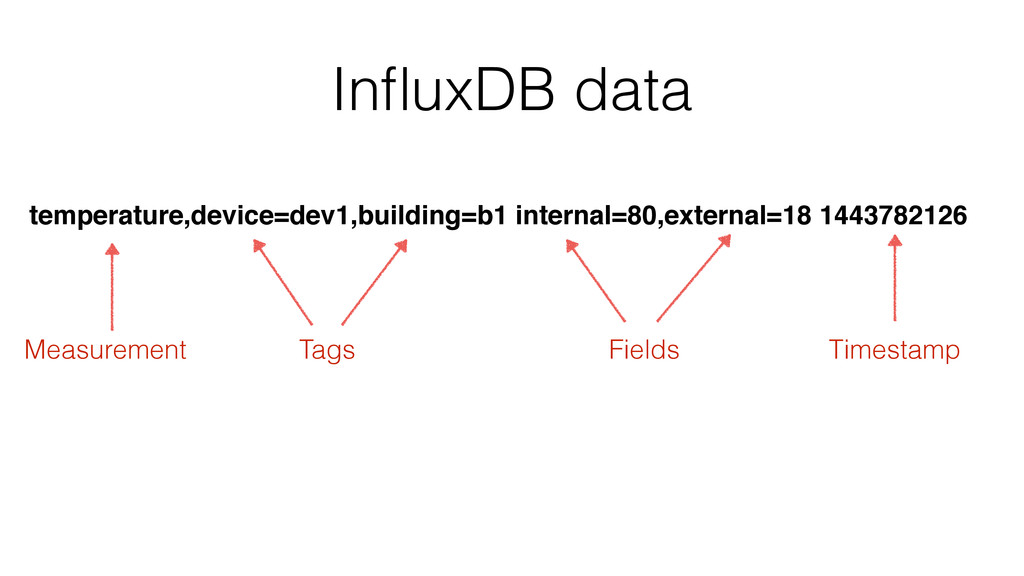
measurement,tag_set field_set timestamp
Ví dụ: cpu_usage,host=server01,region=us-east value=80.5 1600000000
- Measurement: Tương đương "Table" (ví dụ: cpu_usage).
- Tags (host, region): Các siêu dữ liệu được đánh chỉ mục (Indexed). Dùng để lọc nhanh (WHERE clause).
- Fields (value): Dữ liệu thực tế (nhiệt độ, giá tiền...). Không được đánh chỉ mục.
- Timestamp: Thời điểm xảy ra sự kiện.
3. Ưu điểm và Nhược điểm
✅ Ưu điểm (Tại sao chọn InfluxDB?)
- Write Throughput Khủng khiếp: Có thể chịu tải hàng triệu điểm dữ liệu (metrics) mỗi giây trên một node đơn lẻ nhờ cơ chế append-only và TSM.
- Nén dữ liệu siêu việt: Tối ưu hóa chi phí lưu trữ đĩa cứng cho dữ liệu lịch sử.
- Retention Policies (Chính sách lưu trữ): Tính năng "tự hủy" thông minh. Bạn có thể cấu hình: "Giữ dữ liệu chi tiết từng giây trong 7 ngày, sau đó tự động gộp (downsample) thành trung bình 1 giờ và xóa bản gốc đi".
- Truy vấn Time-series chuyên sâu: Hỗ trợ các hàm như moving_average, derivative (đạo hàm), time_shift cực nhanh.
❌ Nhược điểm (Cần cân nhắc)
- Vấn đề High Cardinality (Độ phân tán cao): Đây là "gót chân Achilles" của InfluxDB (các bản cũ). Nếu bạn có quá nhiều Tags (ví dụ: lưu IP người dùng làm Tag), chỉ mục sẽ phình to và nuốt trọn RAM hệ thống.
- Không hỗ trợ Transaction: Đừng bao giờ dùng InfluxDB để lưu số dư tài khoản ngân hàng. Nó không đảm bảo ACID cho các giao dịch phức tạp.
- Hạn chế về Update/Delete: InfluxDB được thiết kế để ghi mới, không phải để sửa đổi dữ liệu cũ. Việc update dữ liệu quá khứ rất tốn kém hiệu năng.
4. Các Use-case phổ biến
- DevOps Monitoring: Lưu trữ metrics từ CPU, RAM, Disk của hàng nghìn server (thường kết hợp với Grafana để vẽ biểu đồ).
- IoT (Internet of Things): Thu thập dữ liệu từ cảm biến nhiệt độ, độ ẩm trong nông nghiệp thông minh hoặc dây chuyền sản xuất (Smart Factory).
- FinTech (Tài chính): Lưu trữ lịch sử giá chứng khoán, tiền ảo (Crypto) để vẽ biểu đồ nến (Candlestick charts) và chạy thuật toán trading.
- Real-time Analytics: Theo dõi hành vi người dùng theo thời gian thực (ví dụ: số người xem livestream từng giây).
5. Minh họa Query (Flux Language)
Từ phiên bản 2.0, InfluxDB giới thiệu Flux - một ngôn ngữ truy vấn dạng kịch bản (scripting), mạnh mẽ hơn SQL truyền thống cho việc xử lý dòng dữ liệu.
Kịch bản: Giám sát nhiệt độ server.
Bước 1: Ghi dữ liệu (Line Protocol)
temperature,location=room1,sensor=t001 value=25.5 1610000000
temperature,location=room1,sensor=t001 value=26.0 1610000060Bước 2: Truy vấn cơ bản (Lọc dữ liệu)
Lấy dữ liệu nhiệt độ trong 1 giờ qua tại room1.
from(bucket: "sensors")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "temperature")
|> filter(fn: (r) => r.location == "room1")Bước 3: Truy vấn nâng cao (Downsampling/Aggregation)
Dữ liệu gửi về mỗi giây quá nhiều? Hãy tính trung bình mỗi 10 phút (Windowing).
from(bucket: "sensors")
|> range(start: -24h)
|> filter(fn: (r) => r._measurement == "temperature")
|> aggregateWindow(every: 10m, fn: mean) // Gộp mỗi 10p thành 1 điểm trung bình
|> yield(name: "mean_temp")Kết luận
InfluxDB đại diện cho sự chuyển dịch tư duy từ "Lưu trữ dữ liệu tĩnh" sang "Quan sát dòng chảy dữ liệu".
Trong kiến trúc hệ thống hiện đại, đặc biệt là Microservices và IoT, giá trị của dữ liệu thường tỷ lệ nghịch với thời gian tồn tại của nó (dữ liệu 5 phút trước quan trọng hơn dữ liệu 5 năm trước). InfluxDB giải quyết bài toán này bằng cách hy sinh tính năng quan hệ (Relation) để đổi lấy tốc độ (Speed) và hiệu quả nén (Compression).
Đối với các kỹ sư phần mềm, việc hiểu và áp dụng InfluxDB không chỉ là giải pháp cho bài toán Monitoring, mà là chìa khóa để mở ra cánh cửa vào thế giới Data Observability - nơi chúng ta không chỉ lưu trữ dữ liệu, mà còn lắng nghe được "nhịp tim" vận hành của cả hệ thống theo thời gian thực.



