
Giải mã Index: Tại sao query vẫn chậm dù đã "đánh" index? 🤔

Là một backend developer, có lẽ anh em đã không ít lần đối mặt với cơn ác mộng mang tên "query chậm". Mỗi khi tìm cách vượt qua cơn ác mộng đó, chắc chắn “index” sẽ luôn là phép màu đầu tiên mà anh em nghĩ tới. Câu thần chú chúng ta thường truyền tai nhau rất đơn giản: "Thêm index sẽ làm cho query nhanh hơn".
Điều này đúng, nhưng nó chỉ là phần nổi của tảng băng chìm. Chắc đã không ít lần anh em tin tưởng và làm theo câu thần chú, để rồi sững người khi thấy query vẫn chạy rất chậm? Vấn đề không nằm ở câu thần chú, mà ở chỗ anh em chưa thực sự hiểu được cơ chế đằng sau nó.
Bài viết này chúng ta sẽ cùng nhau mổ xẻ cấu trúc của một index, vén bức màn bí ẩn và trả lời câu hỏi hóc búa: "Tại sao query của tôi vẫn chậm?".
Database sẽ tìm kiếm dữ liệu như thế nào nếu không có index?
Thao tác đọc/ghi dữ liệu giữa database và ổ cứng không phải được thực hiện theo từng dòng mà là theo một khối gọi là “page” có dung lượng khoảng 8KB-16KB. Để đỡ phải thực hiện nhiều lần vì đọc/ghi dữ liệu xuống ổ cứng là một trong những thao tác tốn thời gian nhất.
Qua thời gian sử dụng, các câu lệnh DML (INSERT, UPDATE,…) sẽ làm cho vị trí của dữ liệu trong các “page” bị xáo trộn cũng như vị trí vật lý của các trang trong ổ cứng sẽ không tuân theo một thứ tự nhất định nào cả.
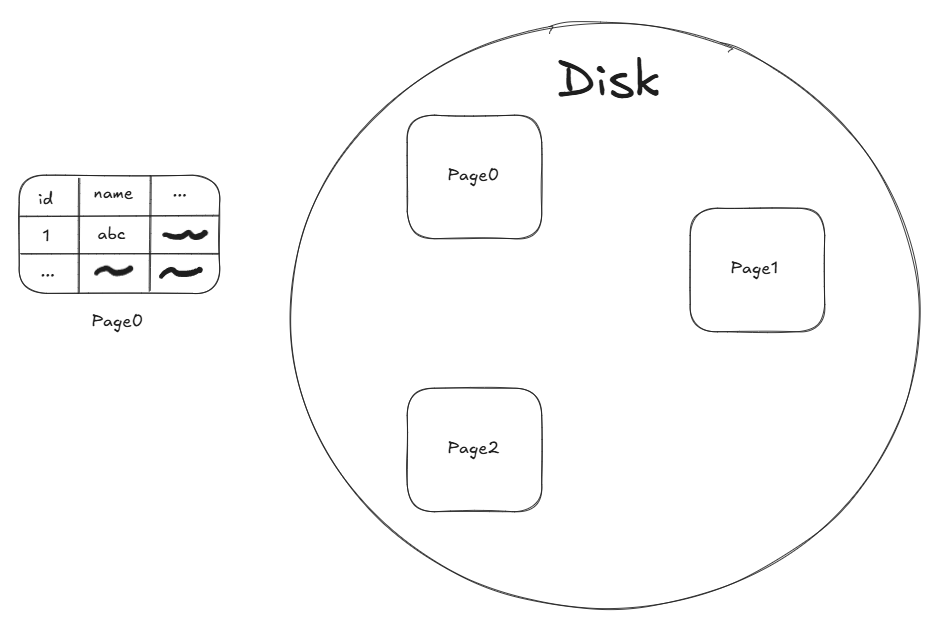
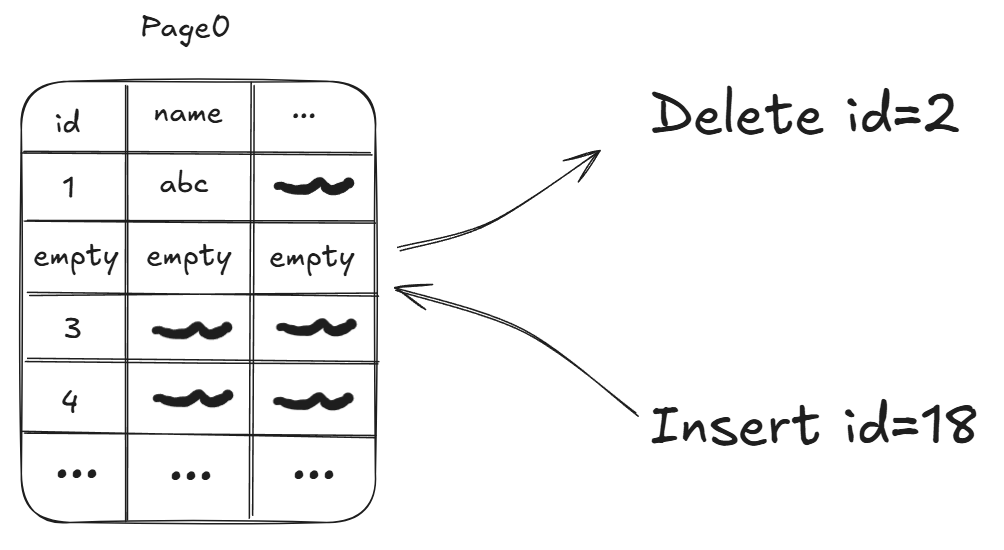
Khi đó nếu anh em muốn tìm một dữ liệu ví dụ như name = “Sydexa”, database sẽ phải quét tuần tự từng “page” một vì nó không thể biết được dữ liệu sẽ nằm trong trang nào, cũng như nằm tại vị trí nào trong trang chứa nó.
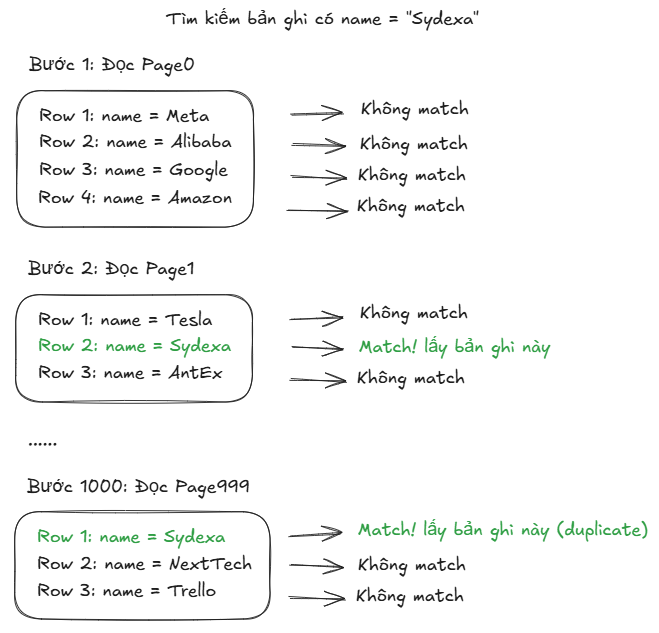
Thậm chí ngay cả khi đã tìm được giá trị cần tìm nó vẫn sẽ tiếp tục quét cho tới trang cuối cùng vì database không thể biết rằng liệu có còn giá trị name = “Sydexa” nào khác nằm ở các trang phía sau không.
Như vậy có nghĩa là nếu có 1000 trang thì sẽ phải thực hiện 1000 thao tác đọc từ ổ cứng, nếu mỗi thao tác đọc mất 10ms thì anh em đã phải mất 10 giây chỉ để tìm kiếm 1 giá trị.
Vì vậy index đã được ra đời nhằm cải thiện hiệu suất trong việc tìm kiếm dữ liệu.
Vậy thì index là gì?
Để hiểu index, hãy bắt đầu với một hình ảnh mà chúng ta đều đã quen thuộc: mục lục của một cuốn danh bạ.
Nếu như nội dung của cuốn danh bạ là dữ liệu được lưu trữ trong bảng, thì mục lục của nó chính là index.

Index hoạt động như mục lục của một cuốn sách, giúp anh em tìm thấy dữ liệu ngay lập tức mà không cần phải "lật" qua từng trang.
Để tìm một số điện thoại, anh em chỉ cần mở mục lục. Ở đó sẽ liệt kê sẵn tên chủ thuê bao kèm theo số trang. Anh em chỉ cần lật tới đúng số trang đó, là thấy ngay số điện thoại cần tìm. Database index cũng hoạt động na ná như vậy.
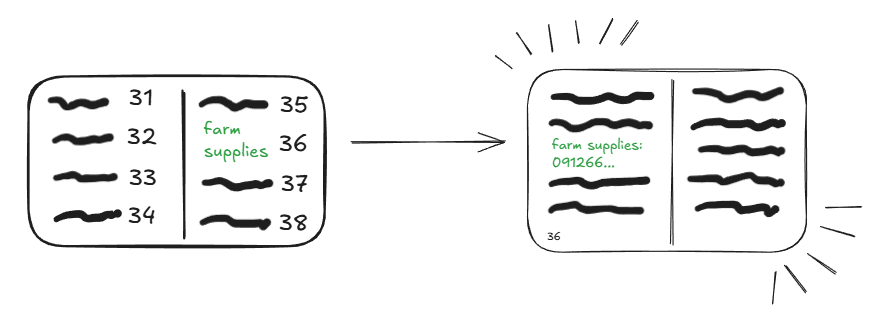
Index cũng được lưu trữ trong ổ cứng theo từng “page” có dung lượng khoảng 8KB-16KB, vì:
- Dung lượng của RAM có hạn, nó không thể lưu toàn bộ các trang index mà nó chỉ có thể dùng cache những trang được sử dụng nhiều thôi.
- Nếu lưu trong RAM, khi gặp sự cố như mất điện thì database sẽ phải xây dựng lại index từ đầu, rất mất thời gian nên cách tốt nhất là lưu trữ nó trong ổ cứng.
Một trang index có chứa hai giá trị, đầu tiên là giá trị của cột (hoặc các cột) được đánh index trong bảng và thứ hai là các giá trị để trỏ tới bản ghi trong bảng.
Nhờ đó nếu như index được sử dụng, database có thể truy xuất bản ghi từ bảng ngay lập tức.
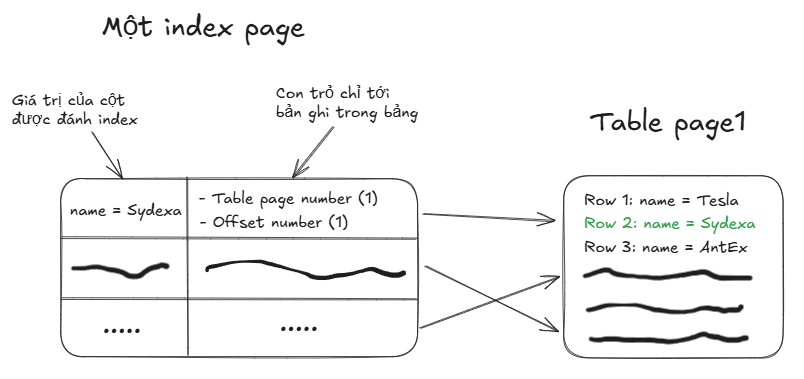
Hmmm, nếu chỉ như vậy thì liệu nó có giải quyết được vấn đề phải quét toàn bộ các trang khi tìm kiếm dữ liệu hay không?
Câu trả lời đương nhiên là không!
Cấu trúc của một index sẽ phức tạp hơn nhiều, hãy cùng sydexa đi từng bước để xây dựng một cấu trúc index hoàn chỉnh nhé.
Đầu tiên chúng ta hãy coi các trang index như một “khối” thống nhất và thực hiện sort dữ liệu bên trong nó theo một thứ tự nào đó.
Dữ liệu giữa các trang index có thể được sắp xếp theo một thứ tự mà anh em chỉ định khi tạo nó.
CREATE INDEX idx_users_name ON users(name ASC);
Khi dữ liệu đã được sắp xếp liền kề, database sẽ duyệt tuần tự từ đầu danh sách cho đến khi gặp giá trị cần tìm. Sau khi xác định được vị trí đầu tiên, việc tìm các bản ghi trùng lặp trở nên đơn giản, database chỉ cần tiếp tục duyệt các phần tử kế tiếp và so sánh với giá trị mục tiêu. Tới khi tìm thấy một giá trị khác ta có thể dừng duyệt và chắc chắn rằng tất cả các bản ghi trùng lặp đã được tìm thấy.

Tuy nhiên, với sự tinh tế và giác quan nhanh nhạy của mình, chắc chắn anh em đã nhận ra kết luận trên có vấn đề đúng không ạ =))
Do index phải được cập nhật liên tục theo thay đổi của dữ liệu trong bảng, nên vị trí vật lý của các trang index trong ổ cứng sẽ không tuân theo một thứ tự nhất định nào cả.
Vậy như trong hình, làm sao database biết được trang index 600 là trang nào, nằm ở đâu để mà sang đấy lấy dữ liệu tiếp theo đem đi so sánh?
Câu trả lời nằm ở sự can thiệp của một cấu trúc dữ liệu mạnh mẽ: Doubly Linked List.
Sau khi liên kết các trang index với nhau theo cấu trúc Doubly Linked List, database sẽ có thể duyệt theo list một cách dễ dàng để tìm ra vị trí của trang 600 dựa trên con trỏ từ trang 599.

Nhờ việc dữ liệu đã được sắp xếp và liên kết bằng cấu trúc Doubly Linked List, chúng ta có thể chắc chắn rằng phía sau bản ghi name = “Sydexa” có table page number (999) tại index page (600) sẽ không còn giá trị trùng lặp với nào khác. Điều này cho phép ta bỏ qua việc quét hàng loạt dữ liệu không cần thiết, giúp tiết kiệm đáng kể thời gian và công sức.
Chúc mừng anh em đã xử lý xong bước đầu tiên trong việc giải quyết vấn đề “phải quét toàn bộ các trang khi tìm kiếm dữ liệu”!!! 🎉🎉🎉

Tiếp theo, hãy cùng bắt tay vào hoàn thiện tác phẩm index của chúng ta để có thể giải quyết triệt để vấn đề này nhé. Việc sử dụng cấu trúc Doubly Linked List là một quyết định rất tuyệt vời, nhưng như chúng ta có thể thấy, để tìm ra được trang index 599, anh em phải duyệt trên list tới 600 lần. Con số này sẽ càng lớn nếu tập dữ liệu của chúng ta càng nhiều.
Vậy khi có một lượng lớn các trang index, làm sao để database có thể tìm ra trang chứa giá trị anh em cần một cách nhanh nhất?
Đây là lúc cấu trúc Balanced Tree "ra trận". Cây này sẽ được xây dựng ngay trên cấu trúc Doubly Linked List mà chúng ta đã có.
Quá trình xây dựng cây diễn ra từ dưới lên theo các bước sau:
Bước 1: Coi các trang index là các leaf node
Mỗi trang index trong Doubly Linked List giờ đây được xem là một leaf node của cây.
Bước 2: Tạo ra các internal node
Để tạo các internal node, ta cần chọn những giá trị phù hợp từ leaf node làm separator key (khóa phân tách). Mục đích là khi tìm kiếm, các giá trị này sẽ giúp định vị nhanh chóng đến leaf node cần tìm.
Có hai cách chọn phổ biến:
- Low-key: Lấy giá trị nhỏ nhất của mỗi leaf node bên phải (trừ node đầu tiên).
- High-key: Lấy giá trị lớn nhất của mỗi leaf node.
Cả hai cách đều cho hiệu năng tìm kiếm tương đương. Tuy nhiên, low-key được sử dụng phổ biến hơn trong các database vì nó tối ưu hơn cho các thao tác ghi:
- Khi insert dữ liệu mới vào cuối một leaf node, không cần cập nhật internal node vì internal node chứa giá trị đầu tiên của leaf node chứ không phải giá trị ở cuối.
- Khi split node (do đầy), việc cập nhật separator key đơn giản hơn.
- Phù hợp cho các thao tác OLTP (Online Transactional Processing), đây là loại workload chủ yếu trong database với tần suất insert/update cao.
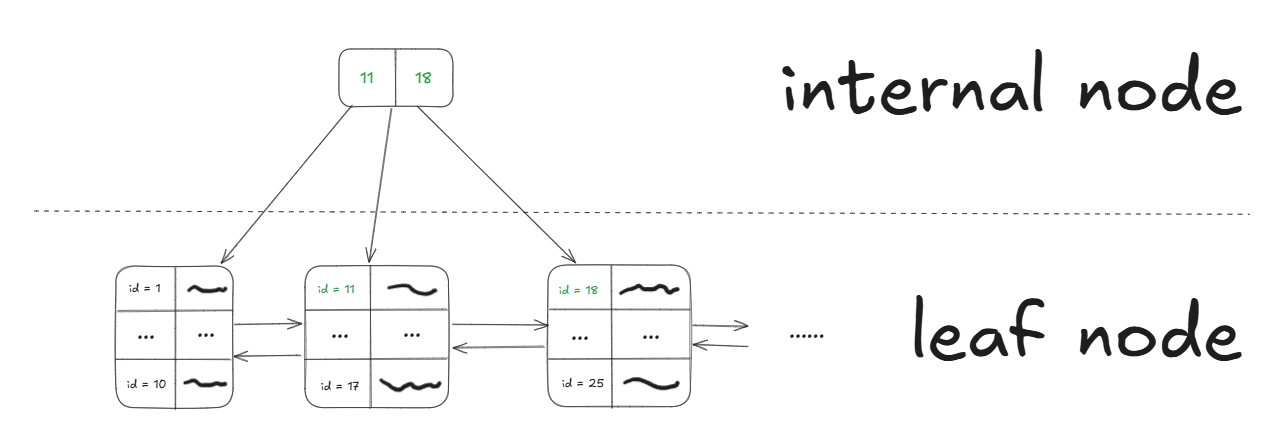
Bước 3: Tạo ra root node
Quá trình này lặp lại ở tầng cao hơn. Hệ thống lại lấy các giá trị đầu tiên từ các internal node để tạo ra một node cấp cao hơn nữa, cho đến khi tất cả được quy về một node duy nhất, đó chính là root node.
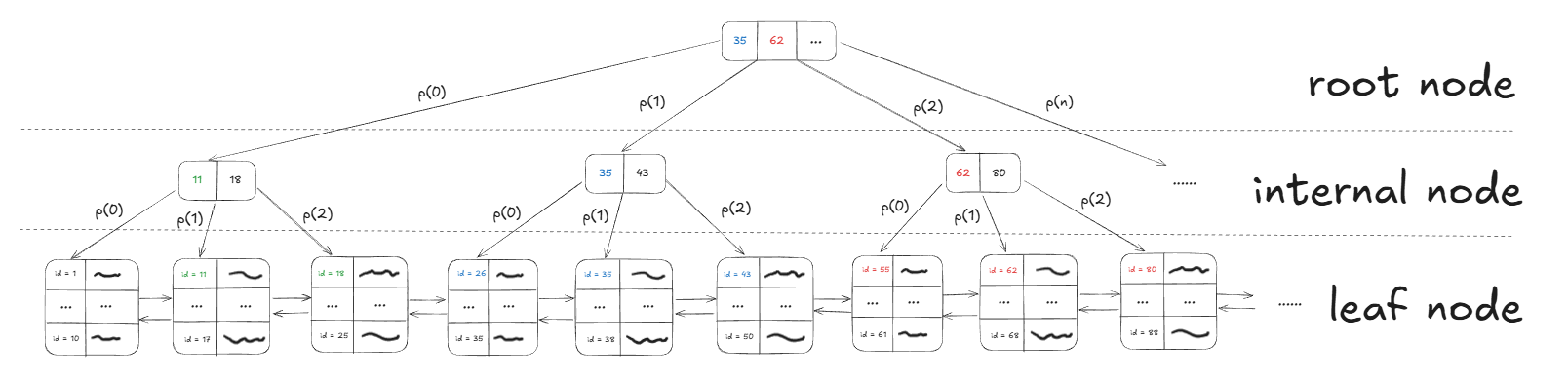
Vì đây là cây cân bằng, khoảng cách từ root node đến bất kỳ leaf node nào cũng bằng nhau (ví dụ trong hình là 2 cấp). Hãy xem quá trình tìm kiếm các hàng dữ liệu có id = “35” diễn ra nhanh như thế nào:
- Duyệt cây: Để tìm các value id = “35”, ta bắt đầu từ root node và lặp lại quy trình sau ở mỗi node:
- So sánh lần lượt từng key trong node hiện tại với value để tìm ra con đường đi đến node tiếp theo cho tới khi đến leaf node.
- Nếu value < key đầu tiên: Đi theo con trỏ P(0) nằm bên trái key đó.
- Nếu value ≥ key cuối cùng: Đi theo con trỏ P(n) nằm bên phải key đó.
- Nếu key[i] ≤ value < key[i+1]: Đi theo con trỏ nằm giữa hai key này.
Từ những quy tắc trên chúng ta có thể thấy database sẽ chỉ cần duyệt cây như sau để đến được leaf node chứa id = “35”: root node(35) → đi theo P(1) → internal node(35) → đi theo P(1) → leaf node(35).
- Quét danh sách liên kết: Tại leaf node này, ta duyệt theo Doubly Linked List sang các node kế cận (cả sau, cả trước) để tìm tất cả các bản ghi trùng lặp có id = “35”.
- Truy cập dữ liệu trong bảng: Dùng con trỏ có sẵn trong mỗi bản ghi tìm được để truy cập thẳng vào ổ đĩa và lấy ra hàng dữ liệu hoàn chỉnh trong bảng.
Đến đây thì xin chúc mừng cuối cùng anh em đã xây được cho mình một cây index hoàn chỉnh với sức mạnh tổng hợp từ Balanced Tree + Doubly Linked List (hay còn gọi là B+Tree index) giúp anh em tìm kiếm dữ liệu với tốc độ chóng mặt, thay vì phải duyệt tuần tự từng trang hoặc tệ hơn là quét toàn bộ bảng như khi không có index.
Quay trở lại với câu hỏi trong tiêu đề “Tại sao query vẫn chậm dù đã đánh index?”.
Sau khi chúng ta hiểu được cấu trúc của một index và sức mạnh nó đã đem lại trong việc truy vấn dữ liệu trong database thì liệu câu hỏi này có trở lên quá ngớ ngẩn? Không thể nào đã đánh index rồi mà truy vấn vẫn chậm đúng không?
Vấn đề là chúng ta thường nghĩ một truy vấn sử dụng index chỉ là bước duyệt cây. Nhưng như đã đề cập tại đoạn trước, nó có tới ba bước, và hai bước sau mới là thủ phạm:
Bước 1: Duyệt trên cây: Luôn luôn nhanh.
Bước 2: Quét danh sách liên kết đôi: Thủ phạm 1
Bước 3: Truy cập dữ liệu trong bảng: Thủ phạm 2.
Chúng ta sẽ phân tích tại sao hai bước cuối cùng mới là nguồn gốc thực sự của các vấn đề về hiệu suất.
Thủ phạm 1: Quét danh sách liên kết đôi (Index Range Scan)
Khi nào xảy ra? Khi query của anh em không tìm một giá trị duy nhất, mà tìm một khoảng hoặc một giá trị xuất hiện rất nhiều lần.
Ví dụ, với câu lệnh:
SELECT * FROM users WHERE status = 'ACTIVE'.
Database sẽ duyệt cây để tìm ngay leaf node đầu tiên có status = 'ACTIVE'. Nhưng trong trường hợp có cả ngàn user khác cũng ACTIVE, nó phải tiếp tục quét ngang theo Doubly Linked List, đọc từng leaf node một cho đến hết.
Hậu quả: Nếu query này trả về lượng lớn dữ liệu trong bảng, việc quét index kiểu này sẽ tạo ra cực nhiều thao tác đọc/ghi và có khi còn chậm hơn cả việc quét toàn bộ bảng. Lúc này, query optimizer có thể nhận định rằng việc quét toàn bộ bảng (Full Table Scan) lại hiệu quả hơn và quyết định không sử dụng index.
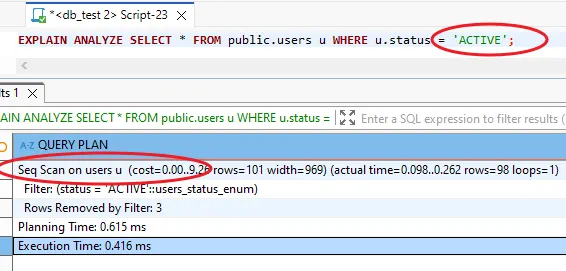
Trường hợp hay bị dính:
- Truy vấn trên các cột có tính chọn lọc thấp (low cardinality), tức là có rất ít giá trị độc nhất như status hoặc gender.
- Thực hiện truy vấn khoảng rộng (range query), ví dụ:
WHERE created_at BETWEEN '2024-01-01' AND '2024-09-01'.
Giải pháp
- Nếu anh em sử dụng Oracle database thì có thể sử dụng BITMAP index. Đây là index được Oracle thiết kế như một giải pháp riêng của họ cho vấn đề low cardinality.
-- Oracle
CREATE BITMAP INDEX idx_status ON users(status);
- Nếu anh em sử dụng PostgreSQL thì chúng ta có thể đánh index kèm với cột có tính chọn lọc cao như create_at.
-- PostgreSQL: Thay vì index riêng trên status
CREATE INDEX idx_orders_status_created
ON orders(created_at, status);
-- Lúc viết điều kiện WHERE created_at = ‘yyyy-mm-dd’ AND status = ‘ACTIVE’ tìm kiếm sẽ hiệu quả hơn
Thủ phạm 2: Truy cập dữ liệu trong bảng (Table Access by Index RowID)
Khi nào xảy ra? Khi anh em SELECT các cột không có trong index.
Ví dụ, trong trường hợp:
Giả sử anh em đánh index trên cột name. Sau đó anh em thực hiện một câu truy vấn SELECT name, email, phone FROM users WHERE name = 'Sydexa' . Nếu truy vấn này tìm thấy 10,000 bản ghi hợp lệ, vì index chỉ chứa giá trị của các cột được đánh index, với từng hàng dữ liệu tìm thấy được, database phải thực hiện một bước truy cập vào bảng vật lý chứa những dữ liệu đó để lấy ra được trường email và phone
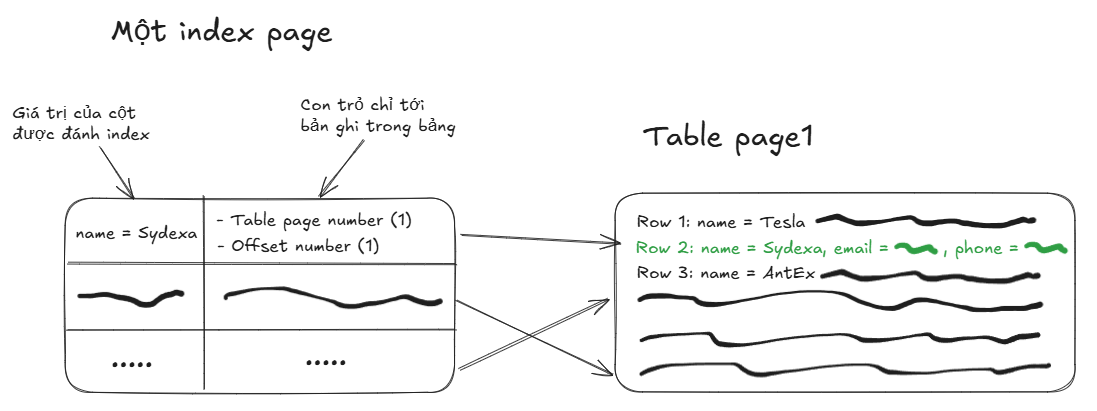
Hậu quả: Dữ liệu trong bảng không được sắp xếp theo thứ tự của index. Điều này gây ra 10,000 lượt truy cập đọc ngẫu nhiên (random I/O) trên ổ cứng, một trong những thao tác tốn kém nhất trong thế giới database. Đây chính là "sát thủ thầm lặng" giết chết hiệu năng của query.
Trường hợp tệ nhất là khi Thủ phạm #1 (Tìm kiếm dữ liệu trên cột có tính chọn lọc thấp) bắt tay với Thủ phạm #2 (truy cập bảng), chúng sẽ tạo ra một "cơn bão" random I/O, khiến query của anh em chậm hơn rùa bò.
Trường hợp hay bị dính:
- Sử dụng
SELECT *một cách vô tội vạ. - Query chọn nhiều cột nằm ngoài index.
Giải pháp:
- Tạo Covering Index: Nếu anh em thường xuyên query một tập hợp các cột cố định, hãy cân nhắc tạo một index bao gồm tất cả các cột đó. Bằng cách này, database có thể lấy toàn bộ thông tin từ index mà không cần phải truy cập bảng.
- Nói không với
SELECT *: Ờ thì cái này là kiến thức mẫu giáo rồi =)).
Chìa khóa để sử dụng hiệu quả bất kỳ công cụ nào một cách hiệu quả là thấu hiểu nó, từ sức mạnh cho đến những giới hạn. Index cũng vậy, nó cực kỳ mạnh mẽ, nhưng không phải là một giải pháp thần thánh. Bằng cách nắm vững bản chất của nó, Sydexa tin rằng anh em sẽ có được sự tự tin và bản lĩnh để đối mặt với bất kỳ lỗi 'oái oăm' nào mà index gây ra trong tương lai.
Xin được gửi lời cảm ơn đến tất cả anh em đã luôn theo dõi và ủng hộ Sydexa trong suốt thời gian qua. Mỗi lượt xem, mỗi bình luận của anh em chính là nguồn động lực khổng lồ để chúng mình tiếp tục hành trình chia sẻ kiến thức này.
Vẫn còn rất nhiều điều hay ho đang chờ chúng ta cùng nhau khám phá. Sydexa hứa sẽ mang đến những nội dung ngày càng chất lượng và thú vị hơn nữa.



